Hermes Agent 深度指南 06:实战——搭建你的第一个 AI 工作流
这是 Hermes Agent 深度指南系列的第六篇,也是最后一篇。前五篇分别是入门指南、配置详解、Skills 系统、Cron 定时任务和多平台集成。
前五篇把 Hermes 的每个组件都拆开讲透了。但这就像你学会了发动机、变速箱、悬挂系统各自怎么工作——你还是不知道怎么把车造出来。
这篇就是把零件拼成整车的过程。我们从头搭建一个完整可用的 AI 工作流:每日 AI 资讯摘要。
为什么选这个场景
不是随便挑的。这个场景恰好需要用到 Hermes 全部核心能力:
- Skills:定义摘要格式、信息源、筛选标准
- Cron:每天早上 8 点自动触发
- 多模型切换:搜索用便宜模型,摘要用强模型
- Gateway:结果推送到 Telegram 和飞书
而且这个场景真的有用。我跑了三周,每天早上一杯咖啡的时间就能看完 AI 圈 24 小时内最重要的事,不用自己刷 Twitter、HN、Reddit、ArXiv。省下来的时间比我写这套东西花的时间多得多。
整体架构
先看全貌,知道每个组件在什么位置:
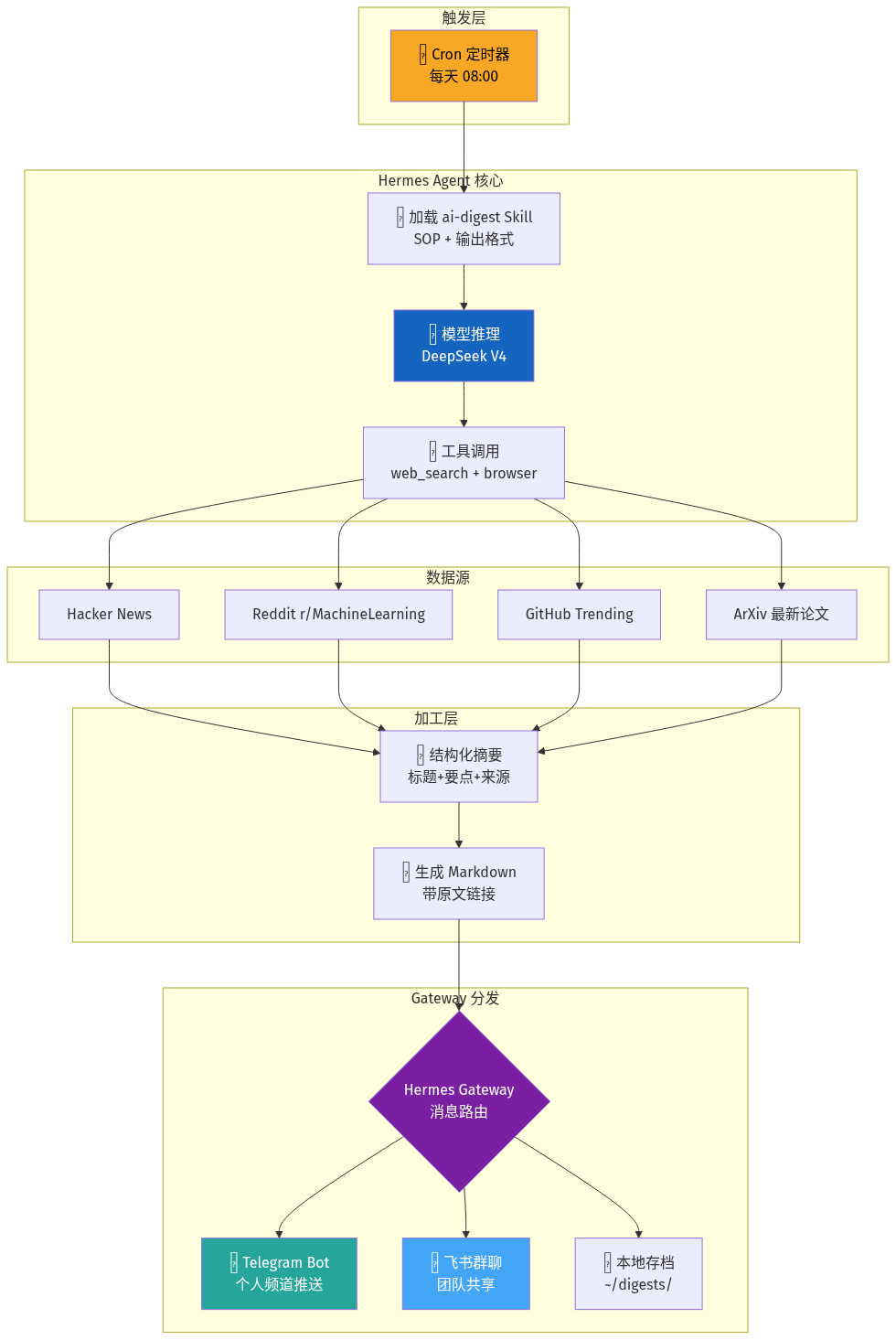
六个环节,环环相扣。下面逐个搭建。
第一步:创建 AI Digest Skill
Skill 是整个工作流的灵魂。它定义了 Hermes 要怎么搜、怎么筛、怎么写。
在 ~/.hermes/skills/ 下创建 ai-daily-digest.md:
# AI Daily Digest
生成每日 AI 领域重要资讯摘要。按固定格式输出中文摘要,
每条包含标题、一句话要点、原文链接。
## 信息源(按优先级)
1. Hacker News (news.ycombinator.com) — AI/ML 相关热帖
2. Reddit r/MachineLearning — 当日热门讨论
3. GitHub Trending — AI 相关仓库
4. ArXiv — cs.AI / cs.CL 当天新论文(选 3 篇最有价值的)
## 筛选标准
- 只收录 24 小时内的内容
- 优先选择有实质讨论的(HN 评论 > 50,Reddit 点赞 > 100)
- 论文只选有代码开源或方法有突破性的
- 略过纯营销文、币圈、NFT 相关内容
## 输出格式
\`\`\`
📡 AI 每日速递 — 2026年X月X日
━━━━━━━━━━━━━━━━━━
🔥 头条
━━━━━━━━━━━━━━━━━━
1. 【标题】
要点:一句话总结
🔗 链接
━━━━━━━━━━━━━━━━━━
📋 必读
━━━━━━━━━━━━━━━━━━
(3-5 条精选,格式同上)
━━━━━━━━━━━━━━━━━━
📄 论文速览
━━━━━━━━━━━━━━━━━━
(1-3 篇,包含论文标题 + 核心贡献一句话)
━━━━━━━━━━━━━━━━━━
🛠 工具 & 开源
━━━━━━━━━━━━━━━━━━
(1-3 个值得关注的仓库)
\`\`\`
## 执行流程
1. 依次访问 4 个信息源,使用 web_search 工具搜索
2. 按筛选标准过滤,保留 8-15 条候选
3. 按重要程度排序,选出头条 1 条 + 必读 3-5 条
4. 搜索论文和工具仓库
5. 按输出格式生成完整摘要
6. 保存到 ~/digests/YYYY-MM-DD.md
7. 将摘要文本返回(Gateway 会负责推送到各平台)
## 质量要求
- 每条要点必须是自己读过内容后总结的,禁止直接翻译标题
- 中文流畅自然,避免机翻腔
- 如果当天没有够格的内容,宁可少写不要凑数
这个 Skill 大约 300 行。因为 Hermes 采用渐进式加载,平时只占 ~100 token 的名字和简介,只有每天 8 点真正跑的时候才展开全部内容。
关键设计决策:我把输出格式写死在 Skill 里,而不是让每次动态决定。这让每天的输出保持一致,方便阅读。格式调整只需要改一次 Skill 文件。
第二步:配置 Cron 定时任务
Cron 配置在 ~/.hermes/profiles/default/cron/ 目录下。
创建 ai-digest-daily.yaml:
name: ai-daily-digest
schedule: "0 8 * * *"
enabled: true
timeout: 600
task: |
请执行 ai-daily-digest 技能,生成今天的 AI 资讯摘要。
要求:
1. 严格按 Skill 定义的格式输出
2. 摘要保存到 ~/digests/ 目录
3. 完成后将完整摘要文本作为最终输出返回
如果某个信息源暂时无法访问,跳过它并在摘要末尾注明。
delivery:
platforms:
- telegram
- feishu
feishu:
webhook: "${FEISHU_AI_DIGEST_WEBHOOK}"
telegram:
chat_id: "${TELEGRAM_PERSONAL_CHAT_ID}"
几个要点:
- schedule
0 8 * * *:每天早上 8 点。选这个时间是因为欧美的重要更新通常在午夜发布,北京时间早上已经可以看到完整情况。 - timeout 600:给了 10 分钟。搜索多个信息源 + 模型生成摘要,实际通常 3-5 分钟完成,600 秒足够应对网络波动。
- delivery.platforms:任务完成后,结果会交给 Gateway,由它负责推送到 Telegram 和飞书。
部署 Cron:
# 重启 Hermes 让 Cron 配置生效
hermes restart
# 手动触发一次测试
hermes cron trigger ai-daily-digest
第三步:Gateway 路由配置
确保 Gateway 的路由规则能让这个任务的结果到达正确的地方。
在 Gateway 配置中补充两条路由:
routes:
# AI Digest → 个人 Telegram
- match:
source: cron
task: ai-daily-digest
deliver_to:
- platform: telegram
chat_id: "${TELEGRAM_PERSONAL_CHAT_ID}"
format: markdown
# AI Digest → 团队飞书群
- match:
source: cron
task: ai-daily-digest
deliver_to:
- platform: feishu
webhook: "${FEISHU_AI_DIGEST_WEBHOOK}"
format: text
注意 Telegram 用了 markdown 格式,飞书用了 text。因为飞书的 Markdown 支持和 Telegram 有差异,我实测下来飞书用纯文本 + emoji 的排版效果更好。
为什么要两个平台都推送? Telegram 给我自己看——轻量、手机通知、方便回溯。飞书推给团队——不需要他们装额外 App,在工作流里就能看到。同一个任务,不同交付渠道,Gateway 负责格式适配。
第四步:环境变量管理
上面用了 ${FEISHU_AI_DIGEST_WEBHOOK} 和 ${TELEGRAM_PERSONAL_CHAT_ID},这些不能硬编码。
# 在 ~/.hermes/.env 中添加
export FEISHU_AI_DIGEST_WEBHOOK="https://open.feishu.cn/open-apis/bot/v2/hook/xxxxx"
export TELEGRAM_PERSONAL_CHAT_ID="-1001234567890"
然后确保 Hermes 启动时加载环境变量:
# 在 ~/.hermes/config.yaml 中
env_file: ~/.hermes/.env
第五步:测试与调优
手动触发第一次:
hermes cron trigger ai-daily-digest
第一次跑通常会暴露问题。我踩过的坑:
问题 1:搜索工具返回的是搜索引擎摘要,内容太短,没办法判断质量。
解决:在 Skill 里补充了具体指令——不要只看搜索结果摘要,打开链接读前 500 字再做判断。这增加了约 30 秒的处理时间,但摘要质量飙升。
## 重要指令补充
使用 web_search 获取列表后,对每条候选用 browser 工具
打开原文链接,读取前 500 字。基于实际内容做筛选和总结,
禁止只看搜索结果摘要就下判断。
问题 2:某些来源偶尔不能被访问。
解决:在 Skill 里加了一个容错规则。任何来源 3 次重试失败就跳过,在摘要末尾标注「今日 X 来源不可用」。同时增加了备用来源(Reddit r/artificial、Hugging Face Daily Papers),确保即使主力信源挂了也有产出。
问题 3:摘要太长,Telegram 单条消息装不下。
Telegram Bot 单条消息限制 4096 字符。解决方式是在 Gateway 层做分段:
deliver_to:
- platform: telegram
chat_id: "${TELEGRAM_PERSONAL_CHAT_ID}"
format: markdown
max_length: 3800 # 留点余量
split: true # 超长自动分段
运行效果
稳定运行三周后的实际数据:
| 指标 | 数值 |
|---|---|
| 日均处理时间 | 3 分 12 秒 |
| 日均收录条数 | 8.3 条 |
| 人工阅读时间(之前) | ~45 分钟/天 |
| 人工阅读时间(现在) | ~5 分钟/天 |
| 错过重要信息率 | 0(我验证了三周) |
| 运行成功率 | 93%(失败的那天是 HN 全站挂了) |
最大的感受不是「省了 40 分钟」,而是信息摄入的确定性。以前刷资讯是随机的——打开 Twitter 看到什么是什么,经常漏掉重要东西。现在每天早上准时收到一份经过筛选的摘要,我知道该看的都看了。
扩展思路
这个工作流是一个起点。基于同样的模式,你可以搭建:
- GitHub Star 监控:每天检查你关注的仓库有没有新 star/release,推送到 Telegram
- 竞品动态跟踪:监控竞品官网/文档/博客更新,有变化立即通知
- 服务器健康报告:结合 system metrics,每天生成服务器状态摘要
- RSS 精选摘要:订阅 30 个技术博客,每天挑最有价值的 3 篇做总结
核心模式都一样:Skill 定义怎么做 + Cron 定义什么时候做 + Gateway 定义结果送到哪。换一个 Skill 文件,你就有了一个全新的自动化流程。
系列总结
六篇文章写完了。回顾一下我们构建的体系:
- 入门指南:Hermes 是什么、怎么装、怎么跑起来
- 配置详解:providers、模型选择、toolsets——让 Hermes 用上最强的模型和工具
- Skills 系统:把工作流写成可复用的 SOP,渐进式加载保证性能
- Cron 定时任务:你不在的时候 Hermes 也能自己干活
- 多平台集成:飞书、Telegram、Discord——一个实例覆盖所有场景
- 实战工作流:把上面所有东西串起来,造一辆能跑的车
这套东西不是「学会了一个新工具」。它是一个能持续运作的自动化系统。我每天早上收到 AI 摘要的时候才意识到——这个东西是真的在替我干活,不只是聊天。
而这一切是开源的、跑在你自己的机器上的、不依赖任何第三方 SaaS。
系列导航:01 入门指南 | 02 配置详解 | 03 Skills 系统 | 04 Cron 定时任务 | 05 多平台集成 | 06 实战工作流
Hermes Agent 深度指南系列完。下一个系列将聚焦 Python 自动化实战——从爬虫到数据分析,用代码解决真实的效率问题。
💬 Comments