Hermes Agent 深度指南 04:Cron 定时任务 — 让 AI 替你值班
这是 Hermes Agent 深度指南系列的第四篇。前三篇分别是入门指南、配置详解和 Skills 系统。如果你还没看过,建议先过一遍——本文会大量用到 Skills 和 toolsets 的概念。
前几篇聊的都是「你跟 Hermes 对话时它能干什么」。但有个场景一直没展开:你不在电脑前的时候,Hermes 能不能自己干活?
答案是能。而且不需要你写 cron 脚本、配 systemd timer、搭 CI pipeline。你只需要用自然语言告诉 Hermes「每天这个时候帮我做这件事」,它到点就自己跑。
为什么不用传统 cron
传统 cron 能干的事有限:
# 传统 cron:能跑脚本、发 curl、写文件——但没法「思考」
0 8 * * * /usr/bin/python3 /opt/scripts/daily_report.py
0 9 * * * curl -X POST -d '{}' https://api.example.com/daily
问题是:你写的脚本逻辑是固定的。数据源变了?格式换了?中间步骤出错了?脚本只会在那儿 crash,不会自己想办法绕过去。
Hermes Cron 不一样。你给的不是一段固定脚本,而是一个任务描述。Agent 在执行时会:
- 先理解任务意图
- 根据当前情况决定用什么工具
- 出错时自动调整策略
- 完成后把结果推送到你指定的地方
换句话说:传统 cron 跑的是代码,Hermes Cron 跑的是判断力。
创建第一个 cron 任务
Hermes 的 cron 管理有两种方式:CLI 命令和配置文件。
CLI 方式(最快上手)
# 交互式创建
hermes cron create
# 命令行直设
hermes cron create "0 9 * * *" "每天早上 9 点抓取 Hacker News 前 10 条,用中文总结后发飞书"
# 查看所有定时任务
hermes cron list
# 查看某个任务的执行历史
hermes cron history <task-id>
# 暂停/恢复
hermes cron pause <task-id>
hermes cron resume <task-id>
# 删除
hermes cron remove <task-id>
创建时会弹出交互式界面,让你选:
- Cron 表达式(有预设模板:每天 9 点、每小时、每周一,不用手写)
- 任务描述(自然语言,写清楚干什么)
- 通知方式(飞书 / Telegram / Discord / 无)
- 绑定的 toolsets(默认用全局配置的,可以覆盖)
- 绑定的模型(比如日常任务用便宜模型)
Cron 表达式速查
Hermes 用的是标准 5 字段 cron:
┌─ 分钟 (0-59)
│ ┌─ 小时 (0-23)
│ │ ┌─ 日 (1-31)
│ │ │ ┌─ 月 (1-12)
│ │ │ │ ┌─ 星期 (0-7, 0和7都是周日)
│ │ │ │ │
* * * * *
几个常用的:
| 表达式 | 含义 |
|---|---|
0 9 * * * | 每天早上 9 点 |
0 9 * * 1-5 | 工作日早上 9 点 |
*/30 * * * * | 每 30 分钟 |
0 9,18 * * * | 每天 9 点和 18 点 |
0 9 1 * * | 每月 1 号 9 点 |
三个实战案例
光讲配置没意思,直接看三个我用过的实际场景。
案例一:每日 AI 资讯摘要
每天早上 8:30,Hermes 自动抓取 Hacker News、ArXiv 和 Reddit r/MachineLearning 的热门内容,用中文写一篇 500 字摘要,发到飞书群。
# 创建任务
hermes cron create "30 8 * * *" "
任务:每日 AI 资讯摘要
步骤:
1. 用 web_search 工具搜索 'Hacker News AI machine learning today'
2. 用 web_fetch 抓取 Hacker News 首页,提取前 10 条 AI 相关新闻标题和链接
3. 用 web_search 搜索 'ArXiv cs.AI new papers today 2026'
4. 用 web_fetch 抓取 r/MachineLearning 热帖
5. 将所有内容整理成以下格式的中文摘要,严格控制在 500 字以内:
📰 AI 晨报 | $(date +%Y-%m-%d)
## 🔥 今日必读
- [标题](链接) — 一句话要点
## 📝 论文速递
- [论文标题](ArXiv链接) — 一句话要点
## 💬 社区热帖
- [帖子标题](Reddit链接) — 一句话要点
6. 用 gateway 推送飞书消息到群聊
注意:如果某个数据源抓取失败,跳过它并在报告末尾注明,不要整个任务失败。
"
这里有几个关键点:
- 任务描述要具体。不是「帮我找 AI 新闻」,而是「搜索 A → 抓取 B → 格式化 C → 推送 D」
- 列出容错策略。最后一句「某个源失败就跳过」是关键——否则 Agent 可能在某个 API 挂了之后反复重试
- 指定输出格式。不给模板 Agent 会自由发挥,给了模板它严格遵循
案例二:博客自动发布 + 社交媒体同步
这是前一篇 Skills 文章的升级版。写了一个 blog-deploy Skill 之后,配上 cron 实现全自动:
# 前提:已经写好 blog-deploy Skill
hermes cron create "0 22 * * *" "
加载 blog-deploy Skill,按 Skill 里定义的流程执行:
1. 检查 content/posts/ 下今天有没有新文章
2. 如果有,执行 hugo --minify --cleanDestinationDir
3. 推送到 GitHub Pages
4. 确认线上已更新(curl -sI 检查 HTTP 200)
5. 如果部署成功,用 gateway 发飞书通知:'✅ 博客已更新:[文章标题]'
6. 如果有新文章,自动生成一条 Twitter/微博风格的推广文案(140 字以内,带博客链接),用 gateway 推送给我审核
"
这个案例展示了 Skill + Cron 的组合技:Skill 定义了「怎么做」,Cron 定义了「什么时候做」和「做完通知谁」。两者职责分离,互不干扰。
案例三:服务器健康巡检
如果你们团队用着几台 VPS,可以让 Hermes 每 4 小时巡检一次:
hermes cron create "0 */4 * * *" "
任务:服务器健康巡检
IP 列表:
- 10.0.1.10 (Web 服务器)
- 10.0.1.20 (数据库)
- 10.0.1.30 (缓存)
用 terminal 工具 SSH 到每台机器,执行以下检查:
1. uptime(负载)
2. df -h /(磁盘使用率)
3. free -m(内存)
4. systemctl is-active nginx/postgresql/redis(核心服务状态)
5. tail -50 /var/log/syslog | grep -iE 'error|fail|oom'(最近错误日志)
汇总要求:
- 负载 > 80% 标红
- 磁盘 > 85% 标红
- 服务非 active 标红
- 错误日志直接贴原文
用 gateway 推送到飞书运维群。
注意:
- SSH 用密钥认证,不要每次输密码
- 如果某台机器连不上,标注 '⚠️ 无法连接' 并跳过后续检查
- 汇总表格化展示,不要一大段文字
"
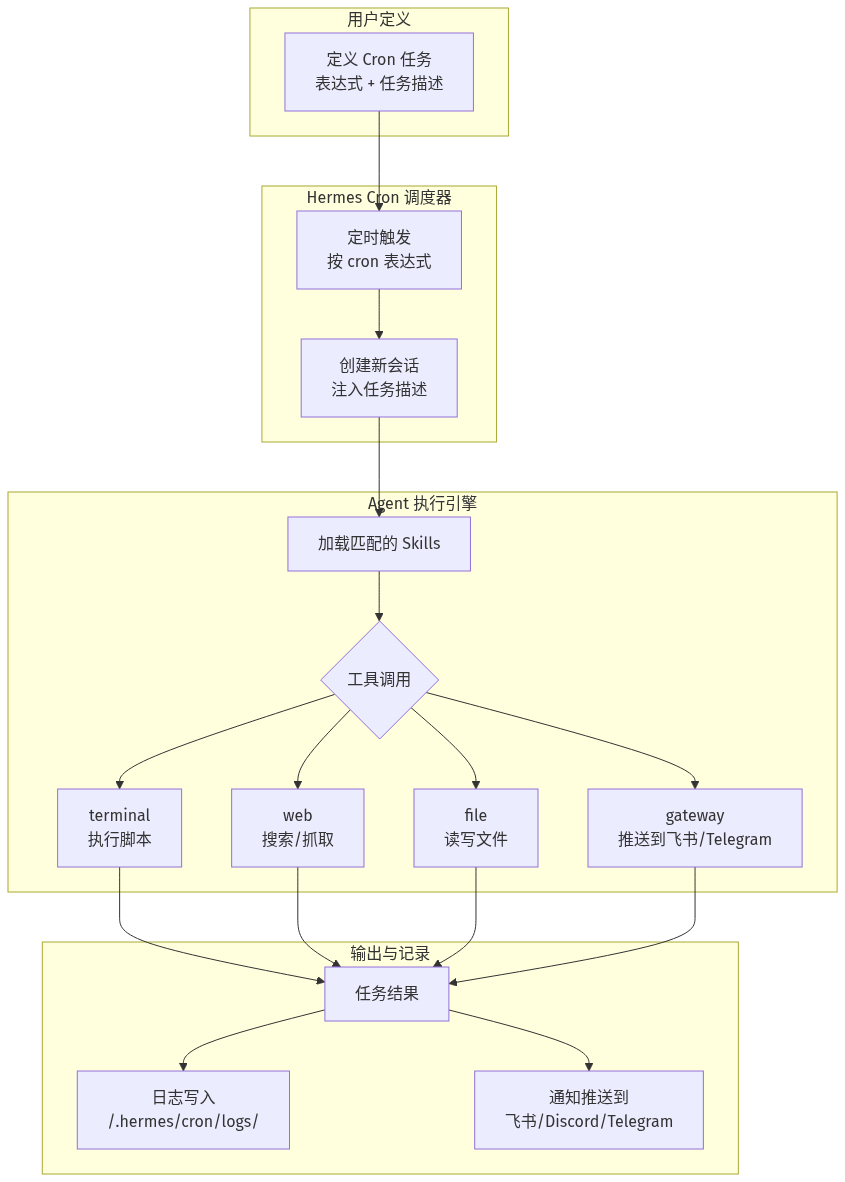
Cron + Skills:真正的自动化闭环
回顾一下前三篇的东西整合起来是什么效果:
Cron 定时触发
→ Agent 加载匹配的 Skills(blog-deploy, douyin-copy-extract...)
→ 按 Skill 定义的 SOP 执行
→ 用配置好的 toolsets 调工具
→ 用配置好的 model 做判断
→ 通过 gateway 推送结果到飞书/Telegram
这已经不是「一个定时脚本」了——这是一个有判断能力的自动化值机员。
配置文件的完整结构长这样:
# ~/.hermes/config.yaml 里的 cron 部分
cron:
enabled: true
log_dir: ~/.hermes/cron/logs/ # 执行日志
max_concurrent: 3 # 最多同时跑 3 个任务
default_notify: feishu # 默认通知渠道
tasks:
- name: daily-ai-digest
schedule: "30 8 * * *"
description: "每日 AI 资讯摘要"
model: deepseek-v4-pro # 指定模型,不指定用默认
provider: deepseek
toolsets: [terminal, web, file]
skills: [news-digest] # 绑定的 Skill
notify:
channel: feishu
webhook_url: ${FEISHU_WEBHOOK}
retry:
max_attempts: 2
backoff: 300 # 失败后等 5 分钟再试
- name: blog-auto-deploy
schedule: "0 22 * * *"
description: "检查新文章并自动部署"
toolsets: [terminal, file, web]
skills: [blog-deploy]
- name: server-health-check
schedule: "0 */4 * * *"
description: "服务器健康巡检"
model: gemini-3-flash # 巡检用便宜模型就够了
provider: google
toolsets: [terminal]
注意 retry 配置:网络波动或 API 临时挂掉是常态,设好重试策略比不设强十倍。
怎么调试 cron 任务
cron 任务是静默执行的,出了事你第一时间可能不知道。几个调试方法:
# 1. 手动触发一次(最常用)
hermes cron run <task-id> # 立刻执行一次,输出实时可见
# 2. 看执行日志
hermes cron log <task-id> # 最近一次执行的完整日志
hermes cron log <task-id> --last 5 # 最近 5 次
# 3. 看 Agent 的推理过程(如果模型支持)
hermes cron run <task-id> --verbose # 打印每一步的思考和工具调用
# 4. 测试通知渠道
hermes cron test-notify <task-id> # 发一条测试消息到配置的通知渠道
最佳实践:先 hermes cron run 手动跑通,再设 schedule 自动跑。别上来就设 0 8 * * * 然后第二天早上看飞书一片寂静——大概率是任务描述有歧义或者工具调用出错,Agent 自己吞了错误。
常见坑
坑 1:任务描述太模糊
❌ 错误写法:「每天帮我看看有什么新鲜事」
✅ 正确写法:「每天 9 点搜索 Hacker News 首页,提取前 5 条标题和链接,用中文写一条 100 字的摘要,发飞书」
Agent 需要明确的输出目标——去哪找数据、怎么处理、输出什么格式、发到哪里。
坑 2:忘了指定 toolsets
cron 任务默认用全局 toolsets 配置。但你的全局可能是「开发模式」,开了 code_execution 和 browser。如果 cron 任务是搜新闻,多出的 toolsets 纯浪费 token。
创建任务时显式指定 -t "terminal,web,file",只给必要的工具。
坑 3:时区问题
Hermes cron 默认用服务器本地时区。很多 VPS 默认是 UTC,你的「早上 8 点」可能变成了「下午 4 点」。
# 先确认时区
date
# 如果不对
sudo timedatectl set-timezone Asia/Shanghai
坑 4:模型余额不足
cron 任务默默跑,余额耗尽了你也不知道。建议:
# 给 cron 任务单独指定便宜模型
hermes cron create "0 9 * * *" "..." --model gemini-3-flash --provider google
# 或者设一个余额告警的 cron 任务
hermes cron create "0 10 * * *" "
查询 OpenRouter API 余额,如果低于 $5,用 gateway 发飞书告警
"
我现在的 cron 配置
分享下我实际在跑的几个任务:
每天 08:30 — AI 资讯摘要 — DeepSeek V4 Pro — 飞书推送
每天 22:00 — 博客自动部署 — DeepSeek V4 Pro — 飞书通知
每 6 小时 — 服务器巡检 — Gemini Flash — 飞书运维群
每周六 10:00 — 清理 ~ 下 30 天未修改的临时文件 — DeepSeek
四个任务加起来,一天的 API 花费大约 $0.30-0.50。换来的是一个 24 小时值班的 AI 助手。
动手试试
最简单的开始:设一个每小时往文件里写一行时间戳的 cron 任务,确认流程跑通
hermes cron create "0 * * * *" "在 /tmp/hermes-heartbeat.log 文件末尾追加一行:'[时间戳] OK'"等一个小时,
cat /tmp/hermes-heartbeat.log看有没有新行。加一点「思考」:改任务描述,让它每小时检查
/tmp/hermes-heartbeat.log的行数,如果超过 24 行(= 跑了一天了),自动清空文件重新开始,并发飞书告诉你「心跳日志已轮转」。接入真实场景:挑一个你每天手动做的重复任务,用自然语言描述清楚,设到 cron 里。观察一周,看是不是真的省了时间。
下一篇文章预告:多平台集成——飞书/Telegram/Discord。Cron 执行完的结果要推送给你,推送的渠道就是这些平台。到时候我们会讲怎么在一个 Hermes 实例上同时接多个平台,以及每条消息怎么做到「该去哪去哪」。
💬 Comments